
Configuring Parameters
Optimizing your foundation model training process
Check This First!This article refers to BaseModel accessed via Docker container. Please refer to Snowflake Native App section if you are using BaseModel as SF GUI application.
As explained in this article, foundation model training requires a YAML config file as an input to pretrain function. Its first major part - data_sources - was covered in depth in previous article of the guide.
We will now focus on the other blocks, ie.:
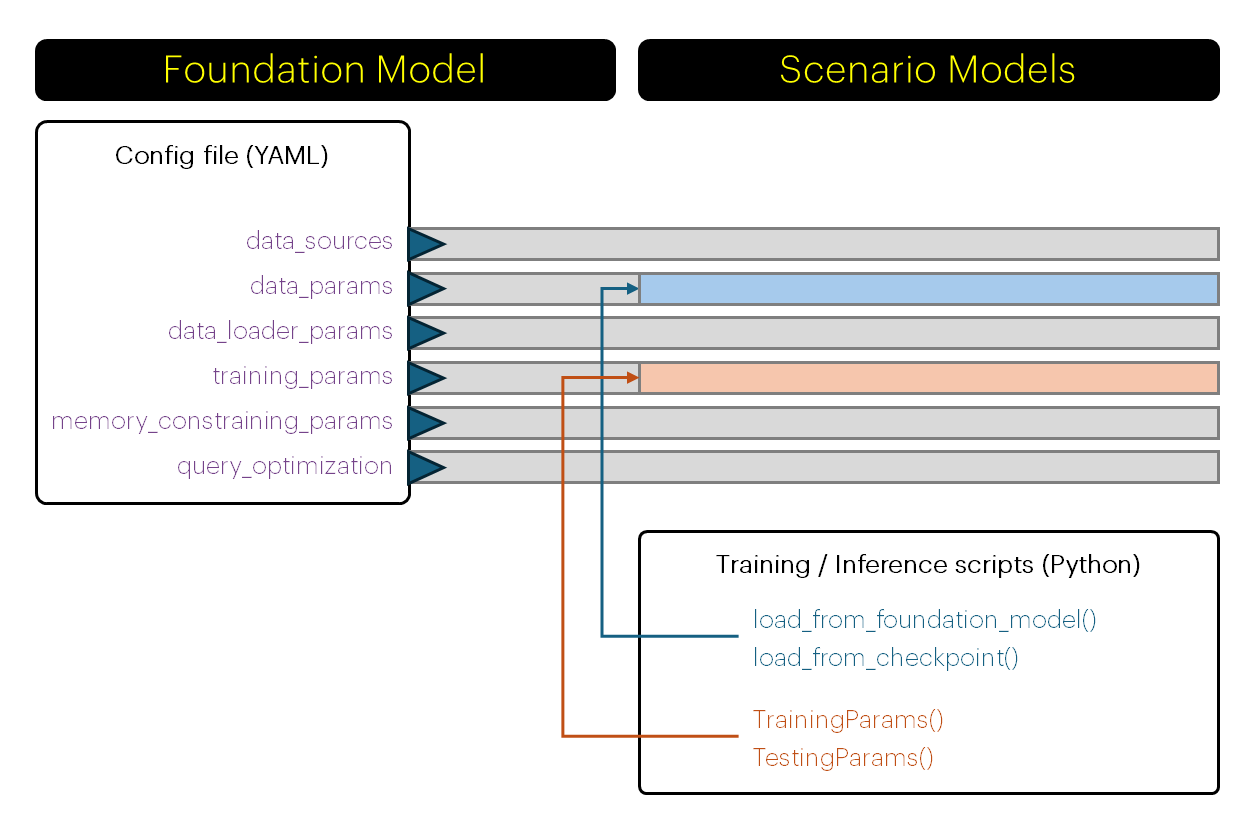
data_params: data related parameters, eg. training / validation / test data splits, sampling, shuffling, caching etc.data_loader_params: parameters that modify how the data is loaded to the model, such as batch sizes, workers etc.training_params: parameters describing the training process, such as learning rate, epochs etc.memory_constraining_params: parameters that control size of the model, eg. the hidden dimension.query_optimization: parameters controlling parallelization, eg. dividing query in chunks.
Please follow the links above to learn more about the options available in each of the sections.
Important!The parameters set in these sections will be applied by default to scenario models created downstream. However, you can expand or modify
data_paramsandtraining_paramsat later stages, to be applied when training scenario models or running predictions.This is described in the following pages:
Please refer to this section for an end-to-end example ofYAML configuration file.
Once the model is fully configured, you can run the training like described in here.
Updated 7 months ago