
Target Function: Time Window and Operations on Events
The imput transformations allowed in functions
Check This First!This article refers to BaseModel accessed via Docker container. Please refer to Snowflake Native App section if you are using BaseModel as SF GUI application.
In this article, we will cover the transformations which we can apply to events and entity attributes in order to obtain the output type and value suitable for your business scenario.
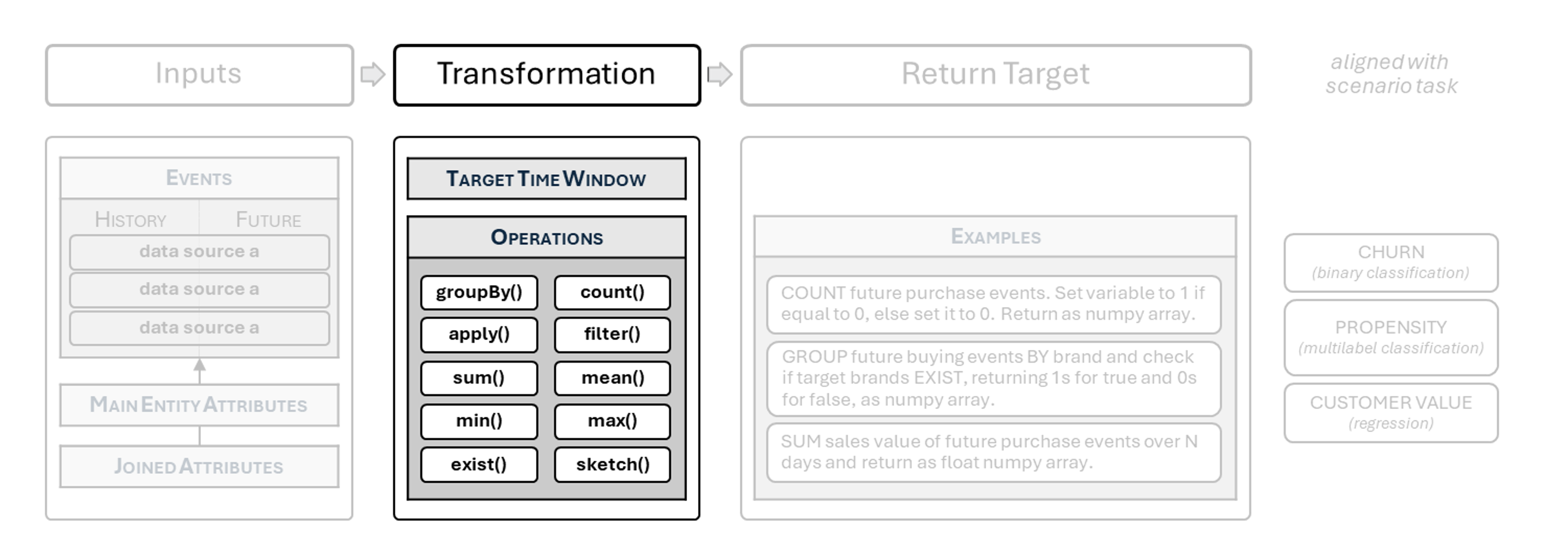
Target Time Window
The foundation model treats all events after the temporal split as "future" and trains to predict them. However, when building scenario models, we typically want the target function to focus on a particular period in the future, such as:
- Which customers will lapse, i.e., fail to make an interaction over a number of days.
- How much a customer will spend over a period of time.
For most scenario models, it is necessary to constrain the future to a specific time window that begins immediately after the temporal split for a given entity. To restrict the future to a desired number of days or hours, you can use the next_n_days or next_n_hours functions, respectively. These functions accept the following parameters:
| Parameters |
|---|
- events: Events
No default
Events to filter. - start: float
No default
The timestamp indicating the starting point for events to be considered after applying the filter. - n: int | None
No default
Number of days or hours to include, or None to return all events afterstarttimestamp.
It is also recommended to return None for those entities where the random split point leaves too short a window to train the model with the appropriate target. It can be achieved with has_incomplete_training_window taking the following parameters.
| Parameters |
|---|
- ctx: dict
No default
Additional information regarding model training is provided here. The_ctxparameter from the target function can be passed directly. - required_days: int
No default
Number of days required for prediction window.
The example below demonstrates the usage of has_incomplete_training_window and next_n_days in practice:
def target_fn(_history: Events, future: Events, _entity: Attributes, _ctx: Dict) -> np.ndarray:
# constrain future events to the next 21 days from split timestamp
target_window_days = 21
# check if training window is incomplete
if has_incomplete_training_window(ctx=_ctx, required_days=target_window_days):
return None
# narrow future events to the defined window
future = next_n_days(events=future, start=_ctx[SPLIT_TIMESTAMP], n=target_window_days)
...Alternatively, you can use the next_n_hours method directly on events from a selected data source. In this case, the function does not require an events parameter and only takes start and n as inputs.
The example below demonstrates how to constrain future transactions events to 21 days.
def target_fn(_history: Events, future: Events, _entity: Attributes, _ctx: Dict) -> np.ndarray:
# define training window length in days
target_window_days = 21
# check if training window is incomplete
if has_incomplete_training_window(ctx=_ctx, required_days=target_window_days):
return None
# narrow future transactions to the next 21 days (24 hours * days)
transactions = future["transactions"]
transactions = transactions.next_n_hours(start=_ctx[SPLIT_TIMESTAMP], n=24 * target_window_days)
...
ExceptionScenario models for recommendation tasks do not predict events over a time window. Instead, they aim to predict the events most likely to happen in the immediate future irrespective of time (e.g., "the next basket").
Trimming the future to a time window should not be performed for recommendation tasks!
from datetime import timedelta
# define time horizon of 14 days starting from the first session timestamp
start = future["sessions"].timestamps[0]
horizon_end = start + timedelta(days=14)
# filter sessions within the defined time horizon
windowed = future["sessions"].filter(
by="timestamps",
condition=lambda ts: start <= ts < horizon_end,
)
# group sessions by calendar day (UTC)
daily = windowed.groupBy(
by="timestamps",
key=lambda ts: ts.date(),
)
# count active days and assign binary label
active_days = sum(1 for _, ev in daily.items() if len(ev) > 0)
label = 1 if active_days >= 3 else 0Custom time-window slicing (new in 0.19)
Alongside next_n_days and next_n_hours, BaseModel now provides a general way to constrain event streams: slice_time_window. This operation takes an explicit start and end timestamp and trims the event streams passed into your target function to that interval.
Use cases include:
- Isolating a campaign or testing period
- Running evaluations on fixed historical ranges
- Debugging target outcomes for known intervals
Semantics
- Half-open interval –
[start, end)includesstart, excludesend. - Empty/out-of-range windows – safe, returns empty events.
- Supported types – numeric Unix timestamps (seconds) or datetimes converted to timestamps.
- Time zones – always use UTC.
- Multiple streams – each stream is sliced independently.
Usage Examples
from datetime import datetime
from monad.targets import slice_time_window
# define time window between 2020-03-15 (inclusive) and 2020-04-05 (exclusive)
start = datetime(2020, 3, 15).timestamp()
end = datetime(2020, 4, 5).timestamp()
# filter future events within the defined time window
scoped_events = slice_time_window(events=future, start=start, end=end)
# the target function now operates only on events between march 15 and april 5, 2020Edge Cases
- start ≥ end → returns empty events.
- Window outside range → empty events.
- Duplicate timestamps → all values with
start ≤ t < endare included.
Best Practices
- Convert datetimes to UTC numeric timestamps before slicing.
- Apply slicing at the target function input level; do not preprocess upstream.
- Use with care when training — slicing reduces available samples and can affect variance.
Interactions
- Target functions – slicing acts as a pre-filter before your computations.
- Temporal splits – can be combined with history/future splits to constrain evaluation periods.
- Date handling improvements – supports numeric date formats and correct boundary handling.
Troubleshooting
- Empty slices → verify timestamp units (seconds vs. ms) and overlap.
- Boundary issues → remember
endis exclusive.
See Also
Operations on events
The following operations can be implemented within the target function directly on event objects, both history and future:
-
count() Calculates the number of events. Returns:
Int, count of eventsExample:
churn = 0 if future['product_buy'].count() > 0 else 1 -
sum(column: str) Sums values for specified column. Argument: a column which values will be aggregated into sum. Returns: float: sum of the values in the specified column.
Example:
future['transactions'].sum(column='purchase_value') -
mean(column: str) Calculates mean value for specified column. Argument: a column which values will be aggregated into mean. Returns: float: mean of the values in the specified column.
Example:
future['transactions'].mean(column='price') -
min(column: str) Finds a min value in a specified column. Argument: a column for which min value will be extracted. Returns: float: min value in the specified column.
Example:
future['transactions'].min(column='purchase_value') -
max(column: str) Finds a max value in a specified column. Argument: a column for which max value will be extracted. Returns: float: max value in the specified column.
Example:
future['transactions'].max(column='purchase_value') -
apply(func: Callable[[Any], Any], target: str) Applies function
functo atargetcolumn. Returns:DataSourceEvents, events with columntargettransformed by thefunc.Example:
future['product_buy'].apply(lambda x: x.lower()), target='brand') -
filter(by: str, condition: Callable[[Any], bool]) Filters events based on the
conditionchecked against columnby. Returns:DataSourceEvents, events filtered based on theconditionchecked against columnby.Example:
future['transactions'].filter(by="PROD_ID", condition=lambda x: x in products_in_campaign) -
groupBy(by: str | list[str]) Groups the events by values in a column (or list of columns) provided after
by. Returns:EventsGroupBy: a proxy object.NotegroupByrequires one of the operators listed in the next section to return anything.Example:
future['product_buy'].groupBy('brand').exists(groups=['Nike', 'Adidas'])
Operations on grouped events
You can also do the following operations applying them to grouped events (EventsGroupBy). This is useful when you want to e.g. check for existence of purchases from categories or brands etc.:
-
count(normalize: Optional[bool] = False, groups: Optional[List[Any]] = None) Counts elements in each group. Arguments:
- normalize : scales counts so that they sum to 1 (boolean, default: False)
- groups : limit grouping to the list provided (a list, default: None)
Returns:
Tuple[np.ndarray, List[str]], a tuple with count of elements per each group and group names.Example:
future['purchases'].groupBy('brand').count(normalize=True, groups=['Garmin', 'Suunto']) -
sum(target: str, groups: Optional[List[Any]] = None) Sums the values of the column
targetin each group. Arguments:- target : a column to apply the grouping operation to (str, required)
- groups : limit grouping to the list provided (a list, default: None)
Returns:
Tuple[np.ndarray, List[str]], a tuple with sum of elements per each group and group names.Example:
future['transactions'].groupBy('category').sum(target='purchase_value') -
mean(target: str, groups: Optional[List[Any]] = None) Computes the mean of the values of the column
targetin each group. Arguments:- target : a column to apply the grouping operation to (str, required)
- groups : limit grouping to the list provided (a list, default: None)
Returns:
Tuple[np.ndarray, List[str]], a tuple with mean of elements per each group and group names.Example:
future['transactions'].groupBy('brand').mean(target='purchase_value') -
min(target: str, groups: Optional[List[Any]] = None) Computes the minimum of the values of the column
targetin each group. Arguments:- target : a column to apply the grouping operation to (str, required)
- groups : limit grouping to the list provided (a list, default: None)
Returns:
Tuple[np.ndarray, List[str]], a tuple with min value of elements per each group and group names.Example:
future['transactions'].groupBy('category').min(target='price') -
max(target: str, groups: Optional[List[Any]] = None) Computes the maximum of the values of the column
targetin each group. Arguments:- target : a column to apply the grouping operation to (str, required)
- groups : limit grouping to the list provided (a list, default: None)
Returns:
Tuple[np.ndarray, List[str]], a tuple with max value of elements per each group and group names.Example:
future['transactions'].groupBy('store').max(target='value') -
exists(self, groups: List[Any]) Checks if any of the
groupsis empty. Arguments:- groups : limit grouping to the list provided (a list)
Returns:
Tuple[np.ndarray, List[str]], a tuple with array indicating existence of the elements per each group and group names.Example:
future['transactions'].groupBy('brand').exists(groups=TARGET_BRANDS) -
apply(self, func: Callable[[np.ndarray], Any], default_value: Any, target: str, groups: Optional[List[Any]] = None) Applies a function
functo each group. Arguments:-
func (Callable[[np.ndarray], Any]): Function to apply.
-
default_value (Any): Default output value.
-
target (str): Column to apply the grouping operation to.
-
groups : limit grouping to the list provided (a list)
Returns: Tuple[Any, List[str]], a tuple with values returned by
funcper each group and group names. Example:future['product_buy'].apply(lambda x: x.lower()), target='brand')
-
Timestamp-based filtering and grouping (new in 0.19)
New in v0.19 — Direct access to date columns Event data sources expose a timestamp field, enabling time-based filtering with
filter()and time bucketing withgroupBy()directly inside target functions.
Notes
- Use UTC timestamps to avoid DST/boundary issues.
- Prefer narrowing with a small time window before grouping for performance.
Filtering by timestamps
Filter events using the built-in timestamps of any stream:
# minimal fragment: filter purchases that happened between two session timestamps
start = future["sessions"].timestamps[0]
end = future["sessions"].timestamps[4] # fifth session boundary
# filter purchases within the defined session window
purchases_between = future["in_game_purchases"].filter(
by="timestamps",
condition=lambda ts: start < ts < end,
)
# assign binary label based on whether any purchases occurred
label = 1 if len(purchases_between) > 0 else 0events.timestampsexposes the underlying date column sorted from the earliest to the latest timestamps.filter(by="timestamps", condition=...)keeps only events satisfying the predicate.
Updated 2 months ago