
Temporal data splits
Learn how BaseModel creates training examples
At training time, the model processes all time-stamped events associated with each entity, restricted to those available within the training set — that is, events between data_start_date and training_end_date.
Whether training_end_date is explicitly defined depends on the setup (production vs. experiment) and the selected holdout strategy. For details, refer to the training, validation and test sets article.
Example creation process
To construct training examples, BaseModel uses timestamps as split points that divide each entity’s event stream into two segments: one for feature creation and one for target generation.
In practice, this means splitting each entity’s event history into “history” and “future”, and training the model to predict the future based on the history.
BaseModel generates input features from raw events on-the-fly using proprietary algorithms.
- History: The portion of past interactions used to compute input features.
- Future: The portion used to derive the prediction target.
How the target is constructed from the “future” segment depends on the training context:
Foundation model training
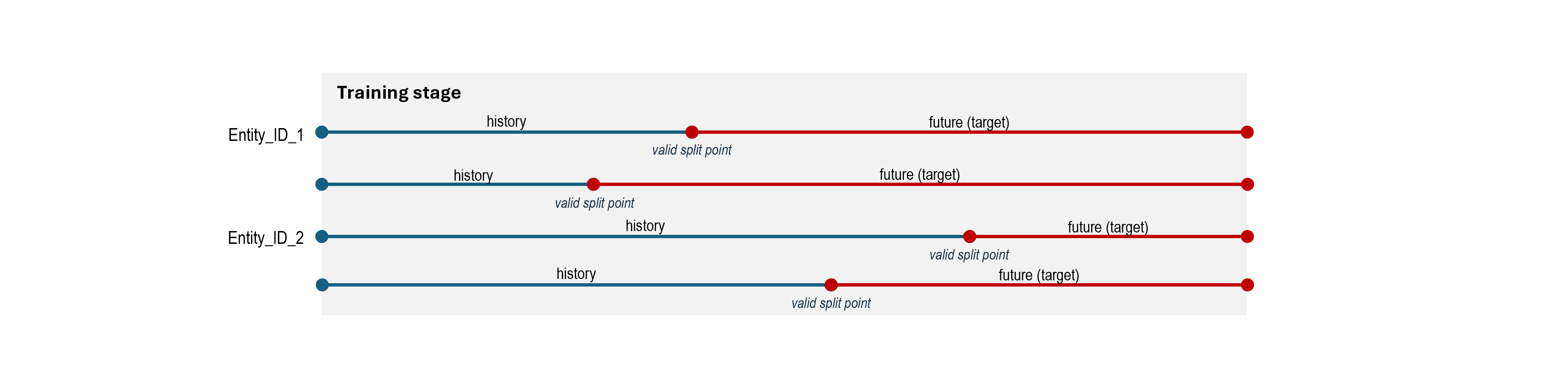
During foundation model training, split points are generated between every pair of events for each entity. Each split point defines a potential training example with the following structure:
- Events from the
data_start_dateup to the split point are treated as history. - Events from the split point up to the
training_and_validation_endare treated as the future and are used as the prediction target.
Each training epoch samples up to maximum_splitpoints_per_entity split points per entity (see below). If more are available, a random subset is selected, and the rest are discarded.
Scenario model fine-tuning (except recommendations)
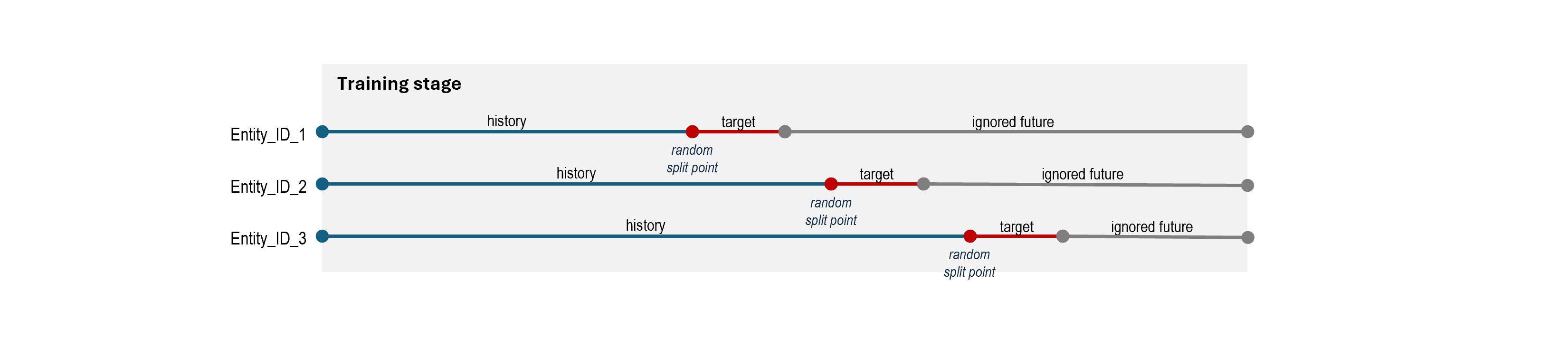
For scenario-specific models (e.g. churn, buying propensity), a target time window is used to define how far into the future the model should make predictions. This window is configured using interval_from.
Recommendation scenario model fine-tuning
In recommendation setups, the model **by default **predicts the next basket — typically the nearest future event — rather than outcomes across a longer time span. (This behavior can be overridden; see the Recommendations Target Function article).
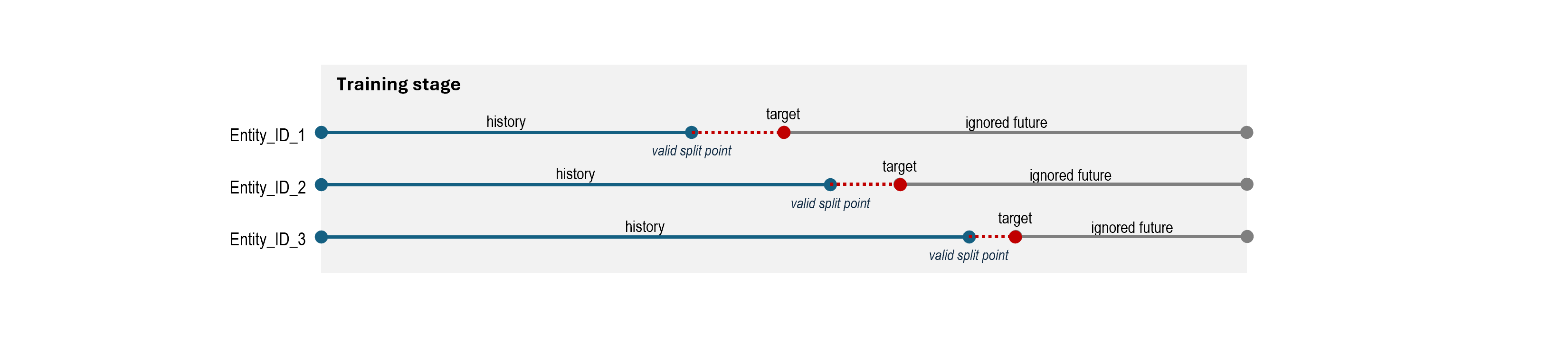
The model then learns to map historical behavior to likely future actions, capturing temporal dependencies and intent patterns.
Customization
The example creation process is highly configurable. A few important parameters include:
target_sampling_strategy: Defines how split points are selected for dividing history and future. You can e.g. restrict the split point selection so that the future always contains some target events (e.g. for recommendation scenarios where the presence of future targets is required).maximum_splitpoints_per_entity: Sets how many split points to sample per entity per epoch. Tuning this helps balance dataset volume, especially when working with highly imbalanced targets, limited number of entities, or particularly large data sets.split_point_data_sources: Specifies which data sources contribute timestamps for split point selection. Useful when your data spans channels with varying temporal coverage. If unspecified, all event sources are included.
This is not an exhaustive list. For full configuration options and behavior, see the data configurations reference.