
Foundation Model Training
Potential issues and resolutions
This stage can be run either as a single pipeline using the pretrain function, or as two separate steps: fit_behavioral_representation followed by train_foundation_model respectively.
The diagram below outlines the stages involved in both flows.
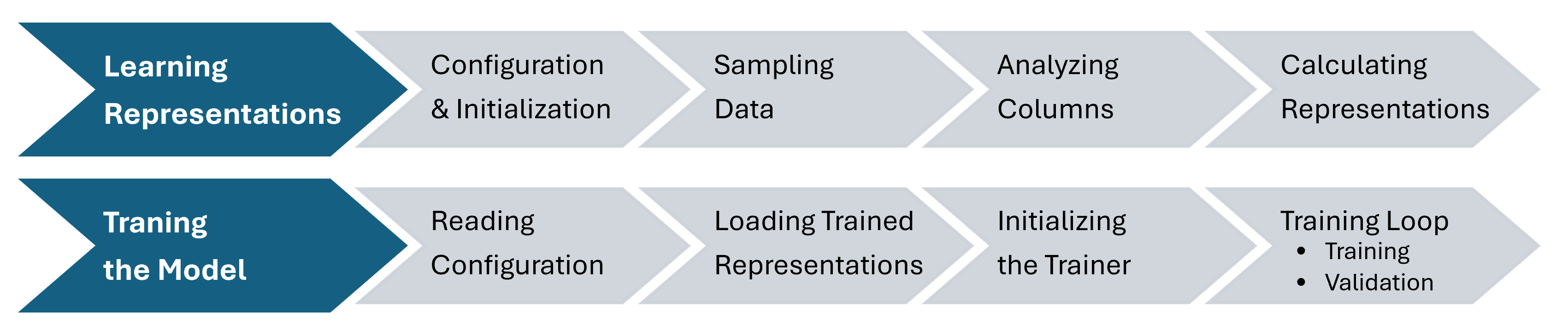
Let’s now look at each step in detail.
Learning Representations (aka. Fitting)
- What happens here:
This stage processes the data and learns internal feature representations. - How to recognize it in logs:
# If run as a full pretrain pipeline, the stage begins with: yyyy-mm-dd hh:mm:ss - INFO - monad.fit: Queuing fit stage and foundation model training # The representation learning process starts with: yyyy-mm-dd hh:mm:ss - INFO - monad.fit: Fitting behavioral representations # The fitting pipeline finishes with: yyyy-mm-dd hh:mm:ss - INFO - monad.fit: Fitted attributes representation. yyyy-mm-dd hh:mm:ss - INFO - monad.fit: Fitting took xxx.yy seconds yyyy-mm-dd hh:mm:ss - INFO - monad.pretrain: Fitting behavioral representation finished. - Remarks
This stage runs in a distributed manner, leveraging Ray to parallelize computations efficiently. The Ray cluster is launched locally on your server—no data leaves the environment. Ensure that the server is appropriately secured against unauthorized access.
Step: Configuration & Initialization
-
What happens here:
Load and validate the YAML configuration file, initialize the representation learning pipeline, allocate system resources, and start required runtime engines such as Ray. -
How to recognize it in logs:
yyyy-mm-dd hh:mm:ss - INFO - monad.run: Running with `overwrite` flag, cleaning dir: yyyy-mm-dd hh:mm:ss - INFO - monad.run: Storing config in output directory... yyyy-mm-dd hh:mm:ss - INFO - monad.run: Processing n columns concurrently. yyyy-mm-dd hh:mm:ss - INFO - monad.run: Using max n workers per column. yyyy-mm-dd hh:mm:ss - INFO - monad.run: Processing will start n workers at most. yyyy-mm-dd hh:mm:ss - INFO - monad.run: Ray available resources {} # list of devices, memory etc. -
What can go wrong:
- Invalid configuration schema
Configuration contains illegal or conflicting entries — such as missing ID/date columns, duplicated or overlapping column definitions, or misuse of shared entity settings. These issues raise a ValueError or ValidationError with a specific problem description.
How to fix it: Acting on these hints should be enough to resolve the problem by correcting or adjusting the relevant section in the configuration file.
- Broken data source logic
Logical issues like non-unique source names, incorrect or cyclic joins, or inconsistent type overrides may prevent the pipeline from initializing. These issues will also raise a ValueError and typically point to the conflicting config fields.
How to fix it: Carefully reviewing the error message and cross-referencing it with your data source configuration is typically sufficient. Acting on the described conflict—such as fixing source types or correcting join keys—should resolve the issue.
- Attempt to join with two SQL Lambda columns
Joining two sources on columns that both use SQL Lambda is not supported. This may result in backend database errors, such as "missing table" or "column does not exist," depending on how the engine compiles the query.
How to fix it: To resolve this, consider one of the following:- Modify the existing column in the data source so it no longer requires a SQL Lambda transformation.
- Add a new precomputed column to the data source that directly matches the join key.
- Create a SQL view on the event source that exposes a clean joinable column, avoiding the need for SQL Lambda in the join.
- Invalid data parameter configuration
Common issues include reversed date ranges, insufficient number of dates provided, overlapping test and training periods, illegal target window sizes (e.g. negative), or conflicting sampling/split strategies. These raise ValueError during early pipeline validation.
How to fix it: Correcting the illegal entries based on the error message should resolve the issue and allow the pipeline to proceed.
- Misconfigured training parameters
Problems such as out-of-bound thresholds, unsupported number of devices, conflicting output formats (e.g. top-k with incompatible task types), or invalid training limits (e.g. negative batch size) can prevent model training. These are caught during trainer initialization and raise a ValueError with detailed hints.
How to fix it: Acting on the validation hints and correcting the conflicting or unsupported settings should be sufficient to fix the problem.
- Invalid configuration schema
Step: Sampling data
-
What happens here:
Connect to data sources and retrieve a sample of entities and corresponding events from the dataset, based on the configured sample size and expected number of events per entity. -
How to recognize it in logs:
yyyy-mm-dd hh:mm:ss - INFO - monad.fit.monad_analyzer: Creating connector for data_source abc yyyy-mm-dd hh:mm:ss - INFO - monad.fit.connectors.sql_connector: Discovering allowed columns in abc... yyyy-mm-dd hh:mm:ss - INFO - monad.fit.connectors.sql_connector: Filtered discovered `allowed_columns`: yyyy-mm-dd hh:mm:ss - INFO - monad.fit.monad_analyzer: Retrieving data sample for abc yyyy-mm-dd hh:mm:ss - INFO - monad.fit.connectors.sql_connector: Entities number used: n yyyy-mm-dd hh:mm:ss - INFO - monad.fit.connectors.sql_connector: Max events number per entity used: n yyyy-mm-dd hh:mm:ss - INFO - monad.fit.monad_analyzer: Data sample shape: (x, y) -
What can go wrong:
- Out-of-memory errors
These typically occur when the sample query tries to load too much data at once. You may see data engine specific errors like the (BigQuery) example below:Resources exceeded during query execution: The query could not be executed in the allotted memory. Peak usage: 100% of limit.
- Query timeouts
Long-running sample queries may exceed execution time limits, especially on large datasets or when the system is under load.
How to fix it:
If errors occur during the sampling stage, your environment may lack sufficient resources to process the data—or you may be hitting system-level constraints, such as query size limits, concurrent query caps, or retry thresholds imposed by the database engine. You can address this by:
- Limiting the number of features (columns)
Useallowed_columnsordisallowed_columnsto exclude features that are unlikely to add learning value.
- Tuning your database environment
Reduce the risk of memory issues or timeouts by optimizing query performance, increasing retry allowances, or requesting higher concurrency quotas and execution limits from your data platform administrator.
- Out-of-memory errors
Step: Analyzing columns
-
What happens here:
Evaluate each column’s usability and determine its data type and appropriate representation strategy. This is based on heuristics like percentage of missing values, cardinality, and inferred type.NoteColumns that could be interpreted in more than one way are processed using only one default encoding. For example:
- Columns containing text will be encoded as categorical or sketch features, depending on cardinality,
- Columns containing decimal values will be treated as numerical features.
BaseModel may suggest reconfigurations via log hints, such as:
Column 'price' appears to be a time series. Consider configuring it as time_series in column_type_overrides.It's up to the user to decide whether to:
- Replace the default representation using
column_type_overrides, or - Add an alternative representation via a
sql_lambdacolumn if both encodings are valuable.
For more information please refer to Data transformations guide.
-
How to recognize it in logs:
yyyy-mm-dd hh:mm:ss - INFO - monad.fit.preprocessing: Analyzing abc type... yyyy-mm-dd hh:mm:ss - INFO - monad.fit.preprocessing: Skipping column abc: column has cardinality under the treshold yyyy-mm-dd hh:mm:ss - INFO - monad.fit.preprocessing: Inferred data columns yyyy-mm-dd hh:mm:ss - INFO - monad.fit.preprocessing: Column bcd, type categorical yyyy-mm-dd hh:mm:ss - INFO - monad.fit.preprocessing: Column cde, type decimal yyyy-mm-dd hh:mm:ss - INFO - monad.fit.preprocessing: Column def, type categoricalCompressed -
What can go wrong:
- Misinterpreted column types
For example, a numeric field may be inferred as categorical if it lacks a decimal part in the database.
How to fix it:
Set the correct data type directly in the database table, expose it via a SQL view with the desired type, or usecolumn_type_overridesin your configuration to force the intended interpretation.
- Suboptimal encoding for text or time series
BaseModel will default to categorical or decimal if no override is set.
How to fix it:- Use
column_type_overridesto specify the intended representation (e.g., text, time_series). - Add a SQL Lambda column if you want both default and custom encodings applied in parallel.
- Use
- Misinterpreted column types
Step: Calculating and saving representations
-
What happens here:
Apply suitable feature calculators and encoders to transform usable columns into learned representations and store them as model features. -
How to recognize it in logs:
yyyy-mm-dd hh:mm:ss - INFO - monad.fit.utils: Inferred temporal groupings: ['A', 'W', 'D'] yyyy-mm-dd hh:mm:ss - INFO - monad.fit.features.calculators.group_division_calculator: Got 1 out of n groups yyyy-mm-dd hh:mm:ss - INFO - monad.fit.features.calculators.group_division_calculator: Performed division of data source transactions into n groups yyyy-mm-dd hh:mm:ss - INFO - monad.fit.features.calculators.group_division_calculator: Group 1. Query: ~('query'). Support x.xxxx yyyy-mm-dd hh:mm:ss - INFO - monad.fit.features.tasks: Computing embeddings fusion yyyy-mm-dd hh:mm:ss - INFO - monad.fit.features.tasks: Running EMDE yyyy-mm-dd hh:mm:ss - INFO - monad.fit.features.calculators.cleora_calculator: Will train cleora for column abc and temporal groupings ['A', 'W', 'D'] yyyy-mm-dd hh:mm:ss - INFO - monad.fit.features.calculators.text_feature_calculator: Will train fasttext for column bcd yyyy-mm-dd hh:mm:ss - INFO - monad.utils.feature_stats: Saving feature stats yyyy-mm-dd hh:mm:ss - INFO - monad.fit.features.tasks: Calling emde_fit_transform with sketch_depth x, width y and optimum_depth z yyyy-mm-dd hh:mm:ss - INFO - monad.fit.utils: Saving column cde description -
What can go wrong:
On the environment / machine where BaseModel is running:
- Excessively long runtime
Representation computation may take significantly longer due to inefficient feature definitions or heavy data operations. - Out-of-memory errors
These often surface as worker errors rather than BaseModel itself. They usually mean that the machine has run out of RAM. A typical example:A worker died or was killed while executing a task by an unexpected system error.
How to fix it:
-
Optimize features
Avoid redundant encodings, especially for sketch-type features (e.g., both product ID and product name representing the same concept). -
Reduce unnecessary cardinality in data
For example, if product IDs contain volume, color, or size information, they should be restructured:- Product ID should represent the core product, e.g. Nike Air Max shoes, or Stanley Hinge Wood Screws,
- Volume, or weight should be passed as a numerical variable in the events source.
- Attributes like color, flavor, or size should be passed as product attributes in attributes table.
-
Tune query performance
Use parameters such asnum_concurrent_featuresandnum_cpusto control parallelism and memory usage as described in Managing space and memory guide. -
Increase available memory
Allocate more memory to the Docker container running the job.
On the data base end:
-
Out-of-memory errors
These typically occur when the sample query tries to load too much data at once. You may see data engine specific errors like the (BigQuery) example below:Resources exceeded during query execution: The query could not be executed in the allotted memory. Peak usage: 100% of limit. -
Query timeouts
Long-running sample queries may exceed execution time limits, especially on large datasets or when the system is under load.
How to fix it:
- Use query chunking
Setnum_query_chunksto split sampling queries into smaller, manageable parts. - Tuning your database environment
Reduce the risk of memory issues or timeouts by optimizing query performance, increasing retry allowances, or requesting higher concurrency quotas and execution limits from your data platform administrator.
- Excessively long runtime
Training the Model
Step: Reading Configuration
-
What happens here:
Load and validate the training configuration. Confirm readiness of upstream outputs (e.g. saved features) and validate output directory structure. -
How to recognize it in logs:
# This phase begins AFTER the following entry: yyyy-mm-dd hh:mm:ss - INFO - monad.run: Fitting behavioral representation finished. # There are no phase-specific log entries unless an error occurs -
What can go wrong:
- We’ve seen no issues so far - but if you report anything unexpected during this phase, we’ll be ready to investigate.
Step: Loading trained representations
-
What happens here:
Load the saved feature artifacts and verify their integrity before use in model training. -
How to recognize it in logs:
yyyy-mm-dd hh:mm:ss - INFO - monad.modalities.modality_artifact: Available datasets [names] yyyy-mm-dd hh:mm:ss - INFO - monad.modalities.modality_artifact: Data sources to load: [names] yyyy-mm-dd hh:mm:ss - INFO - monad.datasets.utils: Set fit columns [aliases] for data source abc. yyyy-mm-dd hh:mm:ss - INFO - monad.datasets.utils: Set fit sql lambdas [aliases] for data source abc. yyyy-mm-dd hh:mm:ss - INFO - monad.datasets.monad_data: Set extra_columns in abc to [aliases] -
What can go wrong:
- The only issues we've seen at this stage have been caused by corrupted artifacts or misconfigured settings in the saved checkpoint.
Please do not modify the checkpoint manually. Doing so may prevent it from loading correctly and result in hard-to-debug failures.
- The only issues we've seen at this stage have been caused by corrupted artifacts or misconfigured settings in the saved checkpoint.
Step: Initializing the trainer and data loading
-
What happens here:
Set up the trainer instance, including model architecture, optimizer, loss function, metrics, and prepare the data loaders for training and validation. -
How to recognize it in logs:
yyyy-mm-dd hh:mm:ss - INFO - monad.run: Training foundation model... yyyy-mm-dd hh:mm:ss - INFO - monad.core.loss_wrappers: Using weighted multi input loss yyyy-mm-dd hh:mm:ss - INFO - monad.core.fm.model_provider: Number of model parameters: n Using bfloat16 Automatic Mixed Precision (AMP) GPU available: True (cuda), used: True TPU available: False, using: 0 TPU cores HPU available: False, using: 0 HPUs You are using a CUDA device ('name') that has Tensor Cores. LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3]You should also see the model summary (example):
| Name | Type | Params | Mode ------------------------------------------------------------------------------------ | model_training_strategy | FoundationModelTrainingStrategy | 0 | train | model | FMNet | 313 M | train | train_loss | MeanMetric | 0 | train | val_loss | MeanMetric | 0 | train ------------------------------------------------------------------------------------ 313 M Trainable params 0 Non-trainable params 313 M Total params 1,254.021 Total estimated model params size (MB) 77 Modules in train mode 0 Modules in eval mode -
What can go wrong:
- Long delay before training begins
After initialization, the process may take a while before entering the training loop. This is often due to memory-heavy data preparation - especially when using large parquet data sources or training across multiple GPUs. - Out-of-memory errors
May occur during data loader setup or model initialization if too many columns are used, or if buffer settings are too aggressive for the available memory.
How to fix it:
- Reduce memory pressure
Lower thewindow_shuffling_buffer_sizeindata_paramsto reduce the memory footprint of data loading. - Limit the number of features
Exclude redundant or low-signal columns usingallowed_columnsordisallowed_columns. - Scale resources appropriately
Consider increasing available memory when training large models or using multiple data sources.
- Long delay before training begins
Step: Training Loop (training and validation)
-
What happens here:
Fit the foundation model by iterating through training and validation batches, epoch by epoch, tracking loss and metrics along the way. Then save the best-performing model, checkpoints, and metrics, marking the end of the foundation model training phase. -
How to recognize it in logs:
Training: | | 0/? [00:00<?, ?it/s] Epoch 0: | | 0/? [00:00<?, ?it/s] Validation: | | 0/? [00:00<?, ?it/s] Validation DataLoader 0: | | 0/? [00:00<?, ?it/s] `Trainer.fit` stopped: `max_epochs=n` reached. 2025-05-06 13:38:31 - INFO - monad.utils.feature_stats: Saving feature stats 2025-05-06 13:38:33 - INFO - monad.run: Training foundation model finished. 2025-05-06 13:38:33 - INFO - monad.run: Pretraining finished. -
What can go wrong:
-
Out-of-memory GPU errors
These typically occur when the model does not fit on GPU. A typical example:torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.49 GiB. GPU 0 has a total capacity of 79.32 GiB of which 922.12 MiB is free.How to fix it:
- Check GPU availability
Verify that the GPU card is not occupied by other processes, you can use thenvtopornvidia-smicommands. - Use multi-GPU training
Setdevicesandstrategyintraining_paramsto enable multi-GPU support. See the Model training configuration guide for details. - Optimize features
Avoid redundant encodings, especially for sketch-type features (e.g., both product ID and product name representing the same concept). - Adjust model size
Usehidden_dim,num_layersoremde_qualityto decrease model size and reduce GPU memory usage as described in Managing space and memory guide.
- Check GPU availability
-
Training is very slow
Training can take a long time to progress between batches or epochs, especially with large models or inefficient data loading.How to fix it:
- Enable multi-GPU training
Use thedevicesandstrategysettings intraining_paramsto distribute the workload. - Increase batch size
If memory allows, raisingbatch_sizecan improve GPU utilization. - Increase num_workers
Increase the number of data loader workers (num_workers) to speed up data loading and improve overall training throughput.
- Enable multi-GPU training
-
Out-of-memory errors on the data base end
These typically occur when the sample query tries to load too much data at once. You may see data engine specific errors like the (BigQuery) example below:Resources exceeded during query execution: The query could not be executed in the allotted memory. Peak usage: 100% of limit.How to fix it:
- Increase the number of workers
Increasenum_workersto make the data queries divided into more parts. - Use query chunking
Setnum_query_chunksto split sampling queries into smaller, manageable parts as described in Managing space and memory guide. - Enable local caching
Setcache_dirto store sampled data locally and avoid re-querying during retries or later stages.
- Increase the number of workers
-