
Training, validation, and testing sets
Learn about data splitting strategies in BaseModel
Effective data splitting is crucial for training and evaluating machine learning models. BaseModel employs structured strategies to divide data into distinct sets, ensuring robust model development and assessment.
Understanding the Three Data Sets
In BaseModel, data is partitioned into three primary sets, each serving a unique purpose:
- Training Set: Used to fit the model's parameters.
- Validation Set: Employed for hyperparameter tuning and early stopping. It helps in assessing the model's performance during training.
- Test Set: Utilized exclusively in experimental setups to evaluate the scenario model's performance on unseen data, providing an unbiased assessment of its generalization capabilities.
Production and Experiment Setups
The utilization of these sets varies based on the deployment context:
- Production: Involves only the Training and Validation sets. The focus here is on minimizing latency and maximizing predictive power.
- Experimentation and Proof of Concept (PoC): Incorporates all three sets to facilitate comprehensive evaluation of scenario models and to identify the most effective modeling approach.
Data Splitting Strategies
BaseModel supports two primary strategies for dividing data:
-
Entity-Based Split
This approach partitions data based on unique main entity identifiers (e.g., customer IDs):- Each entity's entire event history is assigned to a specific set—Training, Validation, or Test—ensuring that the same entity does not appear across multiple sets.
- BaseModel supports splitting based on query, a file with IDs, or defining it with percentage.
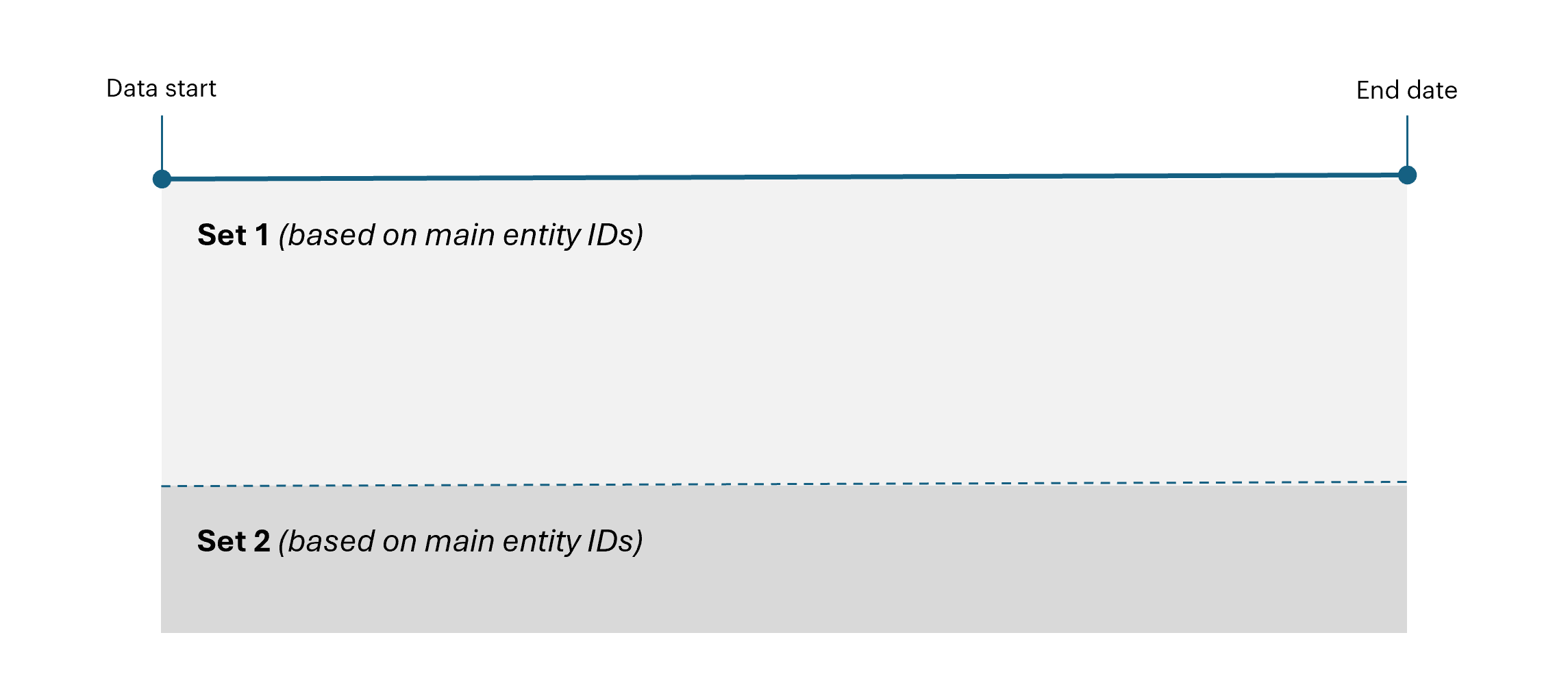
-
Temporal Split
In this method, data is divided based on event timestamps. A specific point in time is chosen to separate events:- Events occurring before the split date are allocated to one set.
- Events occurring after the split date are allocated to another set.
This approach mimics real-world scenarios where future events are predicted based on past data and is particularly suited for behavioral predictions and time-series analyses.
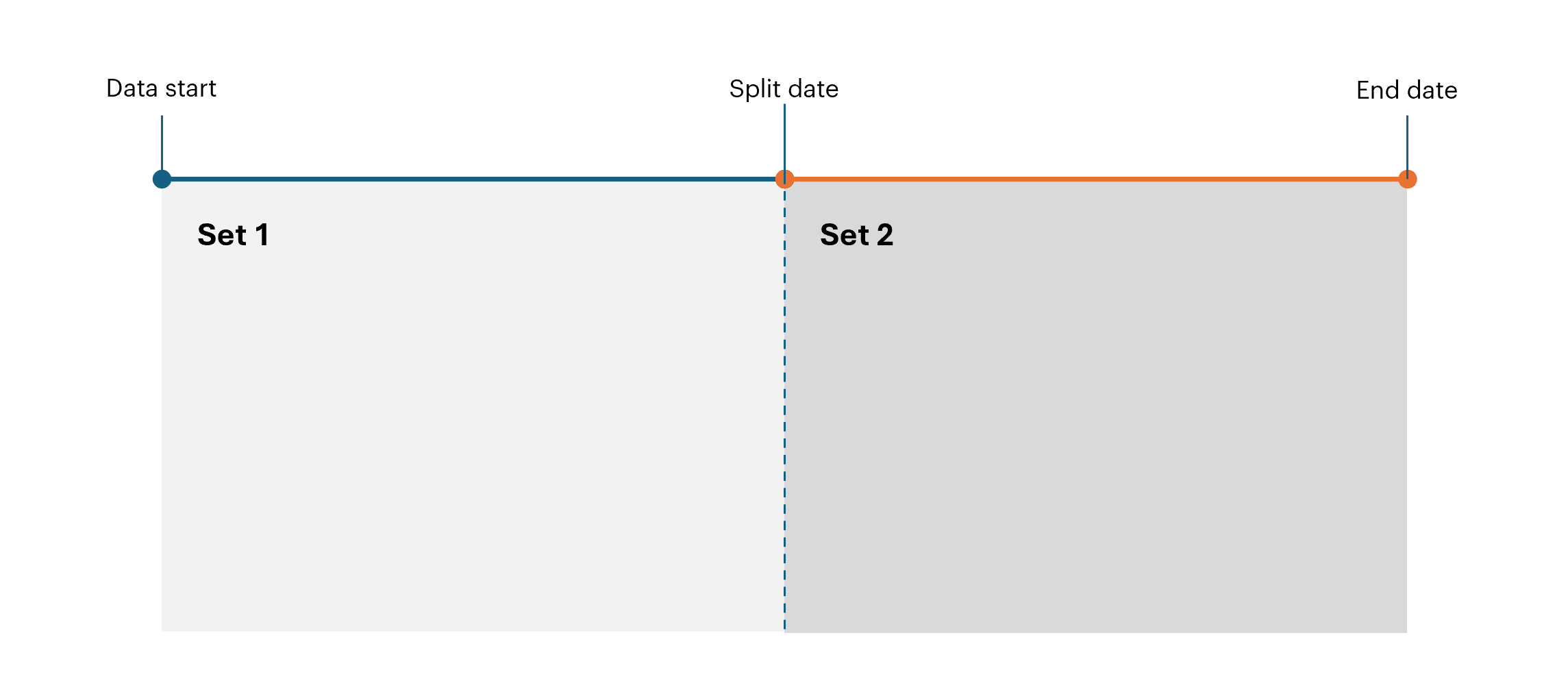
Combining Split Strategies
BaseModel allows for flexible combinations of the above strategies to cater to diverse requirements:
-
Purely Entity-Based Split:
- All sets (Training, Validation, Test) are created by partitioning entities and span the entire duration of the dataset, from
data_start_datetotraining_end_date. - Each main entity ID belongs to only one data set.
- To control how entity IDs are allocated between sets you can upload a file listing IDs assigned to specific sets, define a SQL query that selects IDs to assign to each set, or specify a percentage split, which will randomly assign a percentage of IDs to each set.
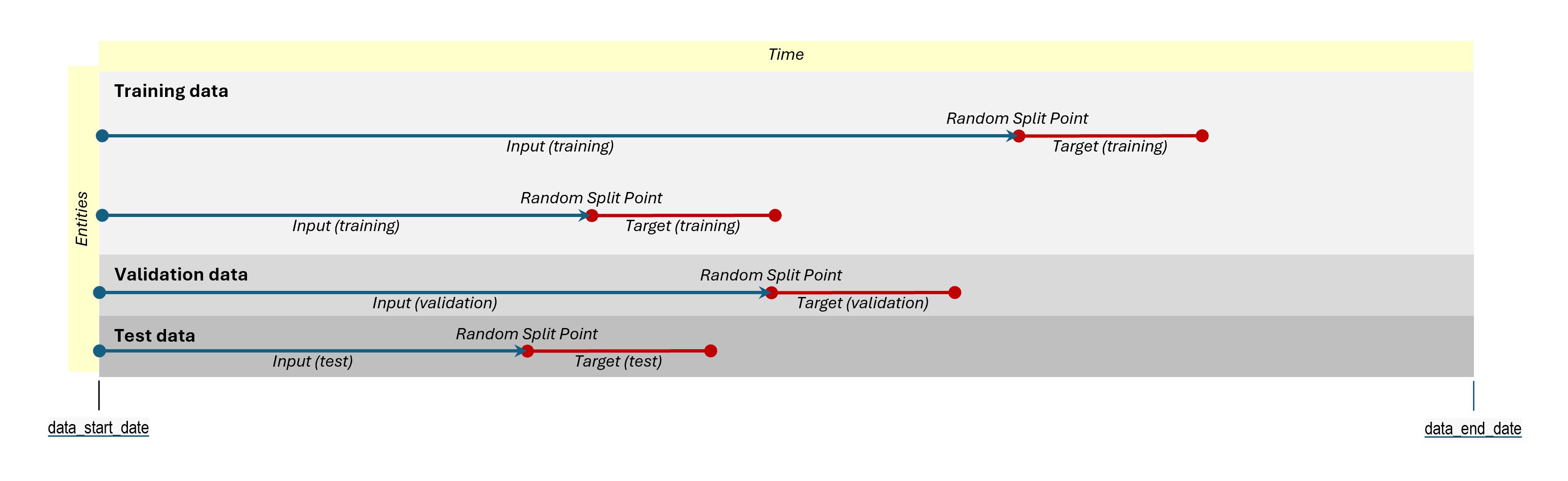
- All sets (Training, Validation, Test) are created by partitioning entities and span the entire duration of the dataset, from
-
Hybrid Split:
- Training and Validation sets are formed using entity-based splitting. The IDs are selected by uploading a file, with a SQL query, or by percentage.
- The Test set is created using a temporal split, separating events based on a specific split date. All main entity IDs are included in the test set.
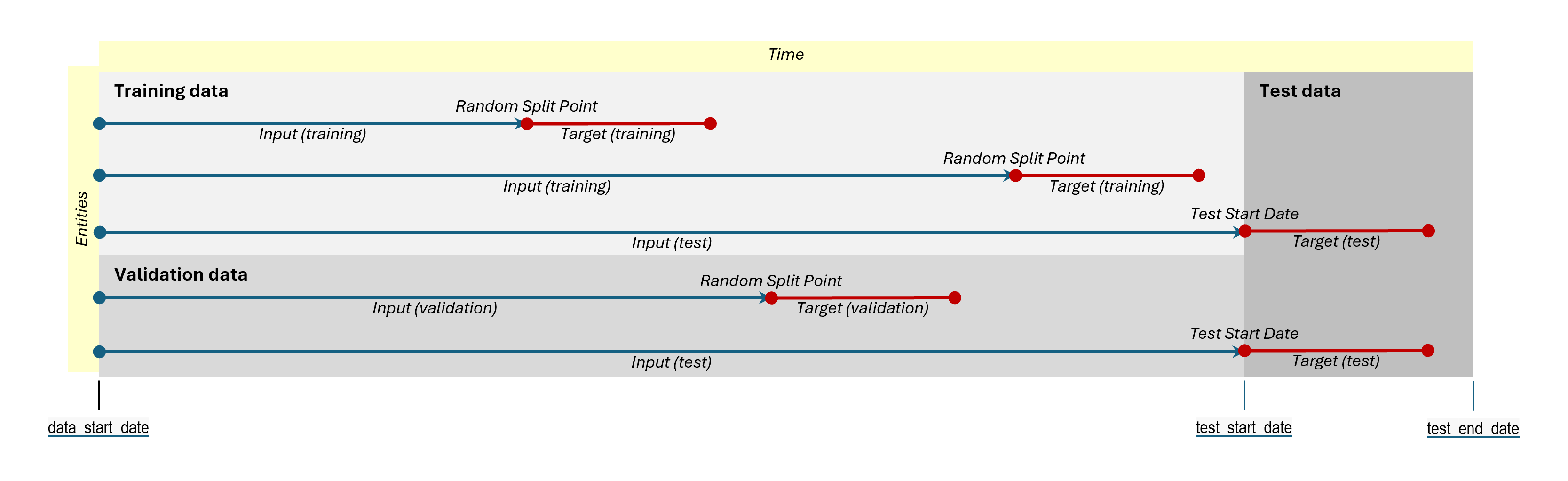
-
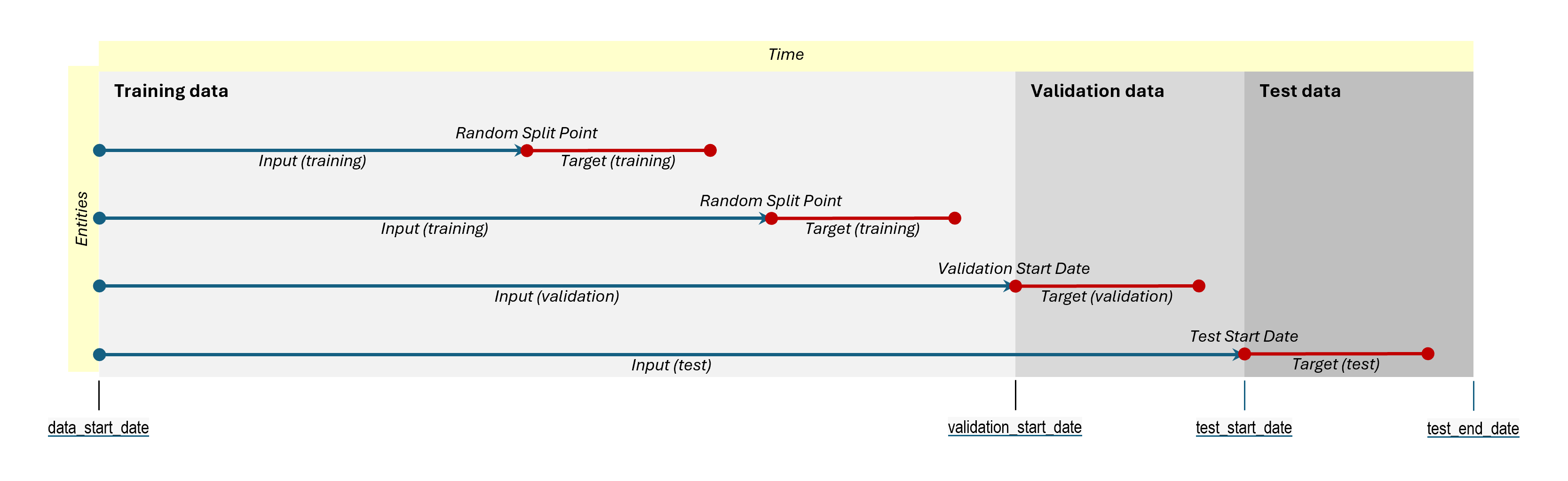
Purely Temporal Split:
- All sets are defined by distinct time intervals.
- Training Period: From
data_start_datetotraining_end_date. - Validation Period: From
validation_start_datetovalidation_end_date. - Test Period: From
test_start_datetotest_end_date.
- Training Period: From
- Note that time periods accumulate progressively, meaning that at each stage the model has access to more historical data. The input and target logic works as follows:
- In the training stage, only events within the training period are used to create both input features and targets.
- During validation stage, input features are built from all events up to the start of the validation period. The model is then validated on its ability to predict events occurring after the validation start date.
- In test stage, input features are built from all events up to the test start date. The model is tested on its ability to predict events occurring after the test start date.
- All main entity IDs are included in all data sets, with no hold-out.
- All sets are defined by distinct time intervals.
This flexibility allows users to tailor the data splitting approach to best fit their specific use case.
NoteWhile the foundation model uses all the events after the split point and up to
training_and_validation_endas the target, during training, validation, and testing phases of a scenario model, either the target time window or (for recommendations) next event is used to define the target. You can read more about it in the Temporal data splits article.
Recommended Configurations
Based on best practices and typical use cases, the following configurations are recommended:
Production:
The focus should be on minimizing latency and maximizing the predictive power of retrained models:
- Utilize an Entity-Based Split.
- Employ only Training and Validation sets .
Experimentation and PoC:
The focus should be on robust evaluation allowing for the identification of the best model configuration:
- By default, adopt a hybrid split:
- Use entity-based splitting for Training and Validation sets.
- Apply a temporal split for the Test set to evaluate the model's performance over time for all main entities.
- Alternatively, depending on specific requirements, a purely Entity-Based or Temporal Split can be employed.
NotePurely entity-based or temporally defined splits when using all three sets in an experimental setup bring some caveats:
- Temporally defined validation periods introduce a break between the last event the model is trained on and the period we make inference for, which may decrease performance in certain circumstances.
- Purely entity-based splitting decreases the number of main entities considered in training, which may decrease performance when the number of entities is limited or classes are extremely unbalanced.