
Temporal data splits
BaseModel Data Management for training, validation, and testing
BaseModel's approach to data splitting to generate train, validation, and test sets is uniquely adapted to behavioral modeling, where we aim to predict future behaviors based on user's past interactions. Here's how we do that:
-
Training, validation and test sets are built using consecutive time windows of events.
Models are trained and battle-tested on the same customer base: we do not hold out any sample of entities. -
At training stage the available user information is split into two sets: the history and the future.
Our proprietary algorithms create model input features on-the-fly from raw data:- The history consists of the interactions based on which we want to predict.
- The future consists of the interactions we want to predict.
Let's look at these procedures in more detail.\
BaseModel data split procedure
This is how BaseModel manages data for training, validation and test:
-
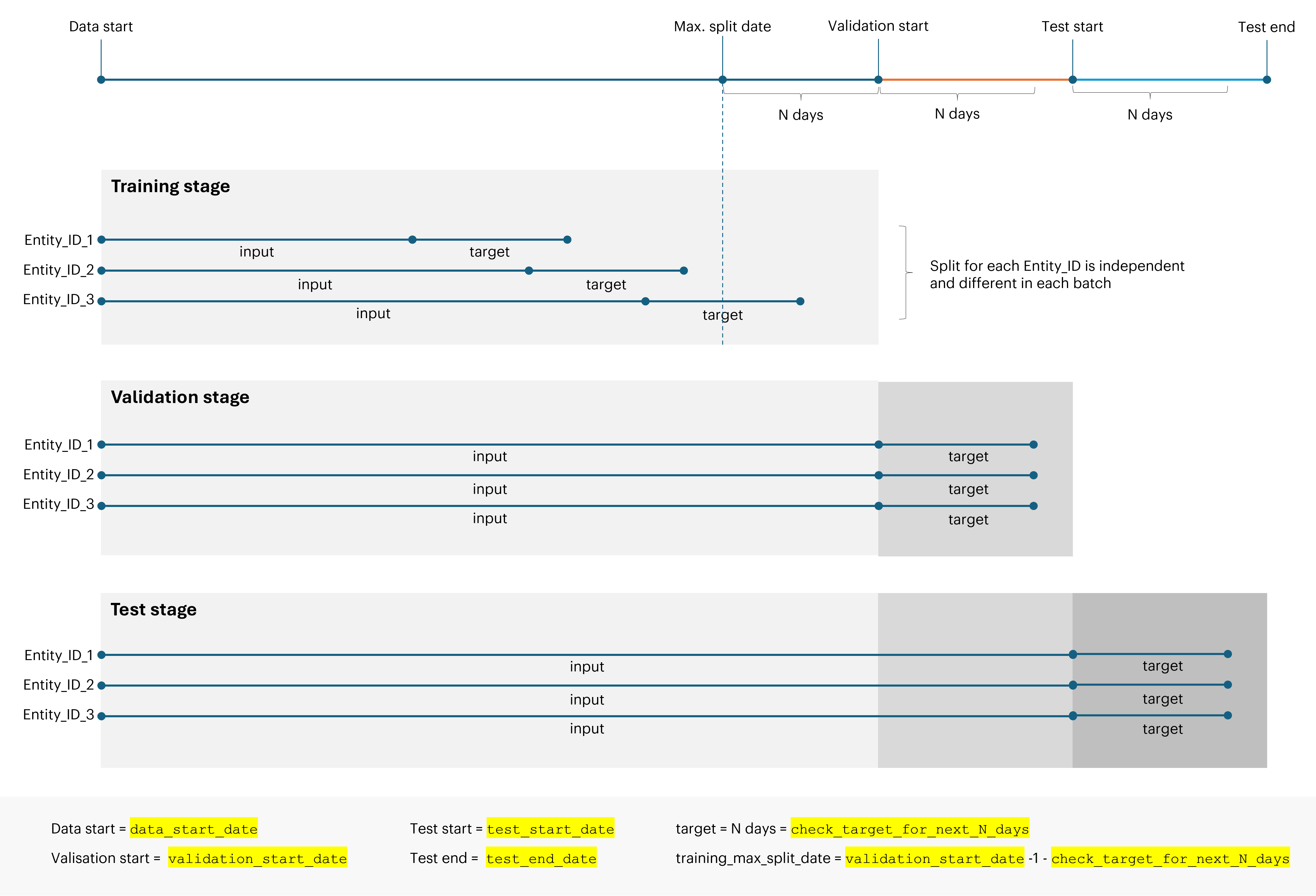
The starting point of our dataset is
data_start_dateparameter; events prior to this date are excluded entirely. -
Data sets for user history in training, validation and test stages are built cumulatively:
-
Training set is bounded by the
data_start_dateandvalidation_start_date.
Events after the latter date are not available for training, and we use them to create targets for validation. -
Validation set is bounded by the
data_start_dateandtest_start_date.
Events after the latter date are excluded both from training and validation. However, when creating model input, we always consider data starting from the data start date.
This means we will use all available data up to the validation start date to create input features, and events after the validation start date are what we want to predict. -
Test set is bounded by the
data_start_dateandtest_end_date.
Again, we will use all available data up to the test start date to create input features, and events after the test start date are what we want to predict and test against.
-
-
All main entity IDs are included in all data sets, with no hold-out.
Please refer to the simple illustration of this concept below:

BaseModel training and validation procedures
The key idea to provide the model with inputs and targets is to use event timestamps as data split points that divide events into two chunks — one to create features and one for targets.
At training stage we randomly generate a split point (independently for every entity and every batch) and consider events from data_start_date until that point as the history, and the events after that date ("future") will be used to create the model's target:
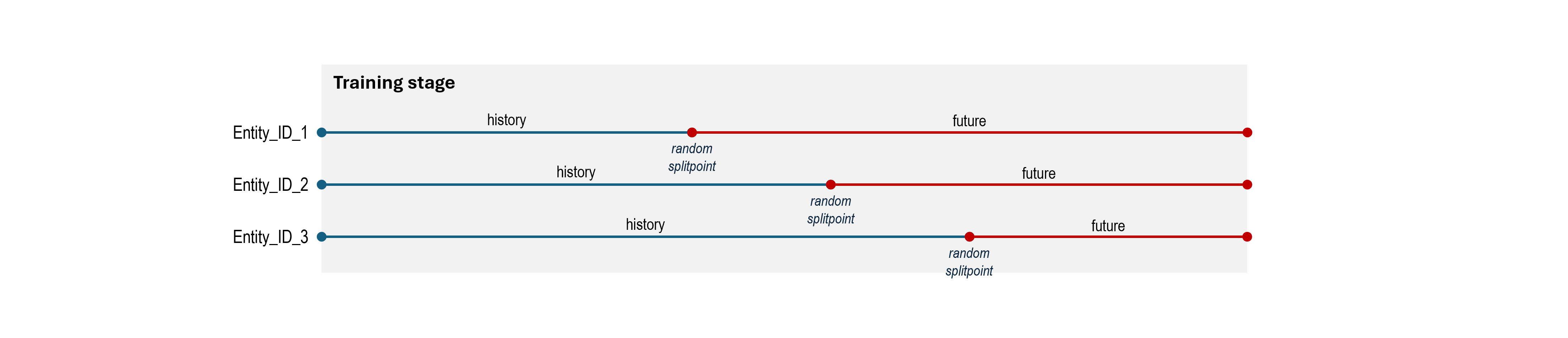
Exactly what portion of "future" events we use to create model target, and the procedure of data split points generation differs slightly depending on business scenario (the type of downstream model we get by fine-tuning the foundation model). This is explained below.
All behavioral modelling tasks except recommendations
We use "future" events over a specific number of days as the target for the model. The target duration is explicitly declared as check_target_for_next_N_days parameter.
At training stage:
-
The period considered as a target must always fit before the validation start date to avoid data leakage that would occur if training target and validation target overlapped. Thus, we need to set the maximum date for split point as:
training_max_split_date = validation_start_date - 1 - check_target_for_next_N_days -
Now, we randomly select split points between
data_start_dateandtraining_max_split_date, to separate user history from target for training purposes.Did you know?
Multiple split points can be selected for one entity. This enables us to create multiple data points from single user history. The number of split points is governed by the
maximum_splitpoints_per_entityattribute.
For validation purpose we use:
- the whole user history from
data_start_datetovalidation_start_dateas model input, - subsequent
check_target_for_next_N_daysfromvalidation_start_dateas the model target.
This way, we use all available history to make predictions, while preventing data leakage by predicting events that were not seen in the training phase.
Analogously, for testing we use:
- history from
data_start_datetotest_start_dateas an input - subsequent
check_target_for_next_N_daysfromtest_start_dateto create the target.
The whole procedure is shown at the diagram below:\
Recommendations
In recommendations problems, instead of considering the next n days as the target, we use the next basket, as this method can improve recommendation system results. Thus:
-
we do not set
check_target_for_next_N_daysparameter, -
training_max_split_datedefaults tovalidation_start_date, -
we manage random split point selection with
target_sampling_strategyinstead:-
the valid sampling strategy requires at least one event in the out-chunk (target),
-
random sampling does not have to fulfill this condition — out-chunks with no events are allowed.
-
-
if we want to set aside test dataset, we must define
test_start_date, otherwise, the whole period will be used.
Please refer to our blog article for more information about temporal splits and sampling strategy.
Updated 2 months ago