
Fine-tuning the Training Process
How to configure the loading and training process?
In this module, we configure model and training parameters of the downstream task, and write the target function that defines the model's target.
By default, the training parameters are defined as in Pretrain config. It means, that:
- Data sources are loaded automatically.
- Dates for training, validation and test sets are defined as in Pretrain config.
- All model training parameters for training downstream task are defined as in Foundation Model.
This is done for simplicity and with the aim of not replicating unnecessary code. However, we understand that parameters set for your downstream task can differ from the ones used in Foundation Model, so we allow to change them.
We dive into two scenarios in the incoming sections.
Loading Foundation Model
In order to load Foundation Model trained in Pretrain phase, you need to use load_from_foundation_model method.
Example for churn model.
from monad.ui.module import load_from_foundation_model
from monad.ui.module import BinaryClassificationTask
trainer = load_from_foundation_model(
checkpoint_path="<path/to/store/pretrain/artifacts>",
downstream_task=BinaryClassificationTask(),
target_fn=churn_target_fn, num_outputs=1
)Example for propensity model.
from monad.ui.module import load_from_foundation_model
from monad.ui.module import MultilabelClassificationTask
trainer = load_from_foundation_model(
checkpoint_path="<path/to/store/pretrain/artifacts>",
downstream_task=MultilabelClassificationTask(),
target_fn=propensity_target_fn, num_targets=10
)Example for recommendation model.
from monad.ui.module import load_from_foundation_model
from monad.ui.module import RecommendationTask
trainer = load_from_foundation_model(
checkpoint_path="<path/to/store/pretrain/artifacts>",
downstream_task=RecommendationTask(),
target_fn=recommendation_fn,
)Creates MonadModuleImpl from MonadCheckpoint where model saved under checkpoint_path is assumed to be a Foundation Model.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| checkpoint_path | str | Directory where all the checkpoint artifacts are stored. | required |
| downstream_task | Task | one of machine learning tasks defined in BaseModel. Possible values are RecommendationTask(), BinaryClassificationTask(), MultilabelClassificationTask(), MulticlassClassificationTask() | required |
| target_fn | Callable[[Events, Events, Attributes, Dict], Union[Tensor, ndarray, Sketch]] | Target function for the specified task. | required |
| pl_logger | Optional[Logger] | Instance of PytorchLightning logger. | None |
| loading_config | Optional[LoadingConfigParams] | A dictionary containing a mapping from datasource name (or from datasource name and mode) to the fields of DataSourceLoadingConfig. If provided, the listed parameters will be overwritten. Field datasource_cfg can't be changed. | None |
Additionally, you can pass any parameters defined in MonadDataParams in order to overwrite parameters configured for Foundation Model training:
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
| features_path | str | A path to the folder with features created during the pretrain phase. | required |
| data_start_date | datetime | Events after this date will be considered for training. | required |
| check_target_for_next_N_days | int | The number of days used to create the model's target. Not suitable for recommendation models. | None |
| validation_start_date | datetime | start date for the validation set | None |
| test_start_date | datetime | The date that the prediction is being calculated for. validation_start_date or test_start_date needs to be provided. | None |
| test_end_date | datetime | End date of the test period - prediction end date. | None |
| timebased_encoding | str | How to encode time based features; available encoding options are "fourier" or "two-hot". | 'two-hot' |
| target_sampling_strategy | str | "valid" or "random" sampling strategy. For Foundation Model it should always be "random". | 'random' |
| maximum_splitpoints_per_entity | int | The maximum number of splits into input and target events per entity. | 1 |
| num_query_chunks | int | This parameter represents the number of segments a query should be divided into. Splitting the query into smaller pieces can help reduce memory consumption on the database end. | 1 |
| use_recency_sketches | boolean | If true then recency sketches are used in training | True |
Training downstream task
Once you loaded the Foundation Model, you should specify checkpoint_dir in MonadTrainingParams and overwrite any default parameters you need.
Constructor parameters for PyTorch Lightning Trainer.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| epochs | int | Number of epochs to train. | 1 |
| learning_rate | float | The learning rate. | 0.001 |
| devices | Union[List[int], str, int, None] | The devices to use. Can be set to a positive number (int or str), a sequence of device indices(list or str), the value -1 to indicate all available devices should be used, or auto for automatic selection based on the chosen accelerator. | field(default_factory=lambda : [0]) |
| accelerator | Literal['cpu', 'gpu'] | The accelerator to use, as in PytorchLightning trainer. | 'gpu' |
| precision | Literal[64, 32, 16, '64', '32', '16', 'bf16', '16-true', '16-mixed', 'bf16-true', 'bf16-mixed', '32-true', '64-true'] | Double precision (64, ‘64’ or ‘64-true’), full precision (32, ‘32’ or ‘32-true’), 16bit mixed precision (16, ‘16’, ‘16-mixed’) or bfloat16 mixed precision (‘bf16’, ‘bf16-mixed’). | DEFAULT_PRECISION |
| limit_train_batches | Optional[Union[int, float]] | How much of training dataset to check (float = fraction, int = num_batches). | 1.0 |
| limit_val_batches | Optional[Union[int, float]] | How much of validation dataset to check (float = fraction, int = num_batches). | 1.0 |
| loss | Optional[Callable] | The loss function to use. If not provided, default loss function for a task will be used. | None |
| metrics | Optional[Dict[str, Metric]] | Metrics to use in validation. If not provided, default validation metrics function for a task will be used. | None |
| checkpoint_dir | Optional[Union[str, Path]] | If provided, points the location where checkpoints will be stored. | None |
| metric_to_monitor | Optional[str] | Decides what metric is responsible for determining the model quality for saving the state dict. | None |
| metric_monitoring_mode | Optional[MetricMonitoringMode] | whether the smaller or greater value of the metric is the better. Possible values are "min" and "max". | None |
| callbacks | List[Callback] | List of additional callbacks to add to training | list() |
| gradient_clip_val | Optional[Union[int, float]] | Gradient clipping value passed to PytorchLightning trainer | None |
| warm_start_steps | int | Number of warm-start training steps used while fine-tuning a supervised model. Ignored if no pretrained model is used. | 0 |
| top_k | int | Only for recommendation task. Number of targets to recommend. Top k targets will be included in validation metrics, it doesn't have impact on model training. Default value: 12. | 12 |
| targets_to_include | List[str] | Only for recommendation task. Target names that should be used for validation metrics, it doesn't have impact on model training. | None |
Task-specific training
BaseModelAI supports a broad range of ML tasks:
Classification Tasks
BinaryClassificationTask— Each data point belongs to one of two categories, e.g. churn prediction; with binary classification task, we use binary cross-entropy with logits loss function.MulticlassClassificationTask— Each data point belongs to one of multiple categories (3 or more), e.g. predicting the user's favorite brand; with multi-class classification, we use cross-entropy loss function.MultilabelClassificationTask— Each data point can be assigned with zero or more labels, e.g. predicting the probability that the user will buy a product in some predefined categories; with multilabel classification task, we use binary cross-entropy with logits loss function.
Recommendation Tasks
RecommendationTask— For each data example, a list of n items is returned, e.g. personalized recommendation of offers or products.
Regression Tasks
RegressionTask— Predict continuous values based on the provided input, e.g. predicting how much the user will spend in the next year; with regression task, we use cross-entropy loss function.
Data
Data split
For training purposes, BaseModelAI can split data into train, validation, and test sets. It is done based on events' time windows configured for each phase. The data_start_date is our dataset's starting point — only events after this date will be considered.
To create train, validation, and test sets, we use subsequent dates validation_start_date and test_start_date to define targets. At each stage, we consider user history from data_start_date; what differs are split points that define which portion of events will be used as an input and which will be used to create the model's target.
In configuration file of the downstream task, you must set at least validation_start_date or test_start_date.
Important:If you do not set
validation_start_datebut settest_start_date, you cannot train downstream task, only run prediction using already trained downstream model.
Classification and regression
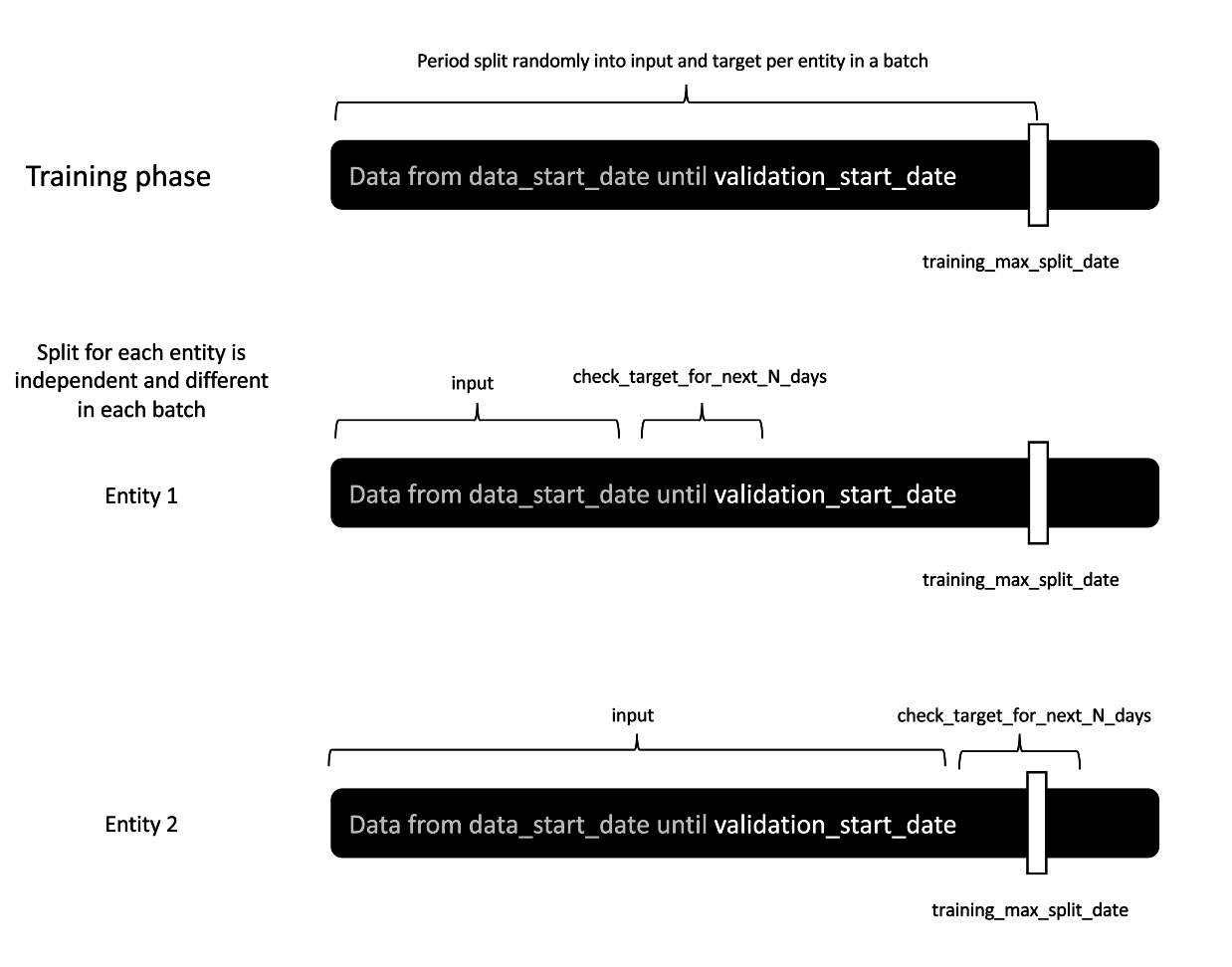
For training purposes, we consider user history since data_start_date until training_max_split_date, which is automatically calculated based on validation_start_date:
training_max_split_date = validation_start_date - 1 - check_target_for_next_N_daysWe randomly select split points between data_start_date and training_max_split_date. Thanks to that, if the latest possible split point is chosen — the one on training_max_split_date — we train on the next check_target_for_next_N_days which are NOT included in the validation period, so no data leakage occurs. Multiple split points can be selected for one entity. The number of split points is governed by the maximum_splitpoints_per_entity attribute. This enables us to create multiple data points from single user history.
Analogously, for testing, we use history from data_start_date to test_start_date as an input and use subsequent check_target_for_next_N_days to create the target.
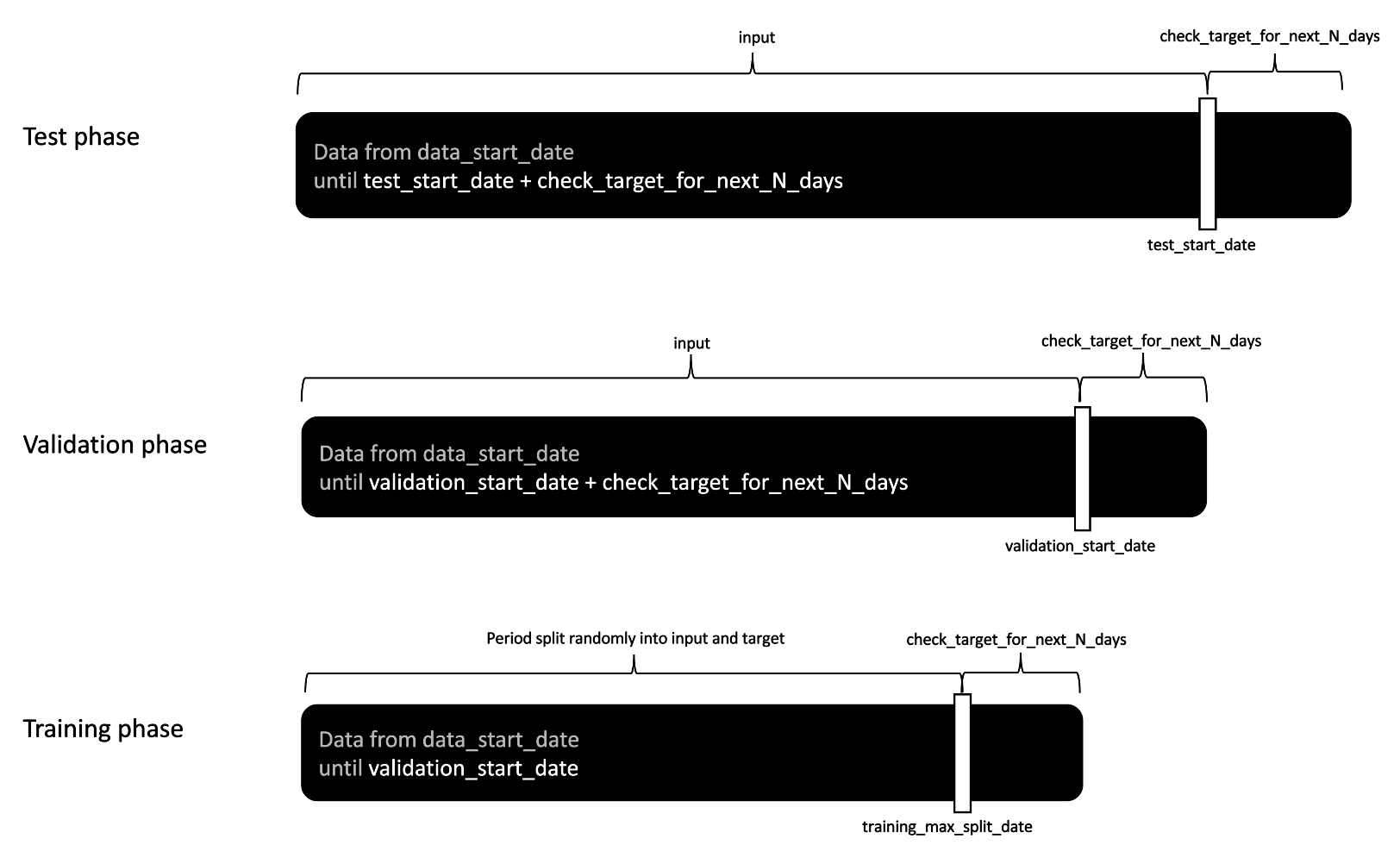
For validation purposes, to create the model input, we use the whole user history from data_start_date to
validation_start_date. To create the target, we use check_target_for_next_N_days after validation_start_date. This way, we use all available history to make predictions, while preventing data leakage by predicting events that were not seen in the training phase.
Recommendations
In recommendation setup, we predict the next item in the basket, so we do not set check_target_for_next_N_days parameter, because it is not relevant.
For recommendations, training_max_split_date defaults to validation_start_date.
If we want to set aside test dataset, we must define test_start_date. If not, the whole period will be used.
Target function
Please refer to the Model Target Function section for details on how to create the target function that will fulfill your business needs.